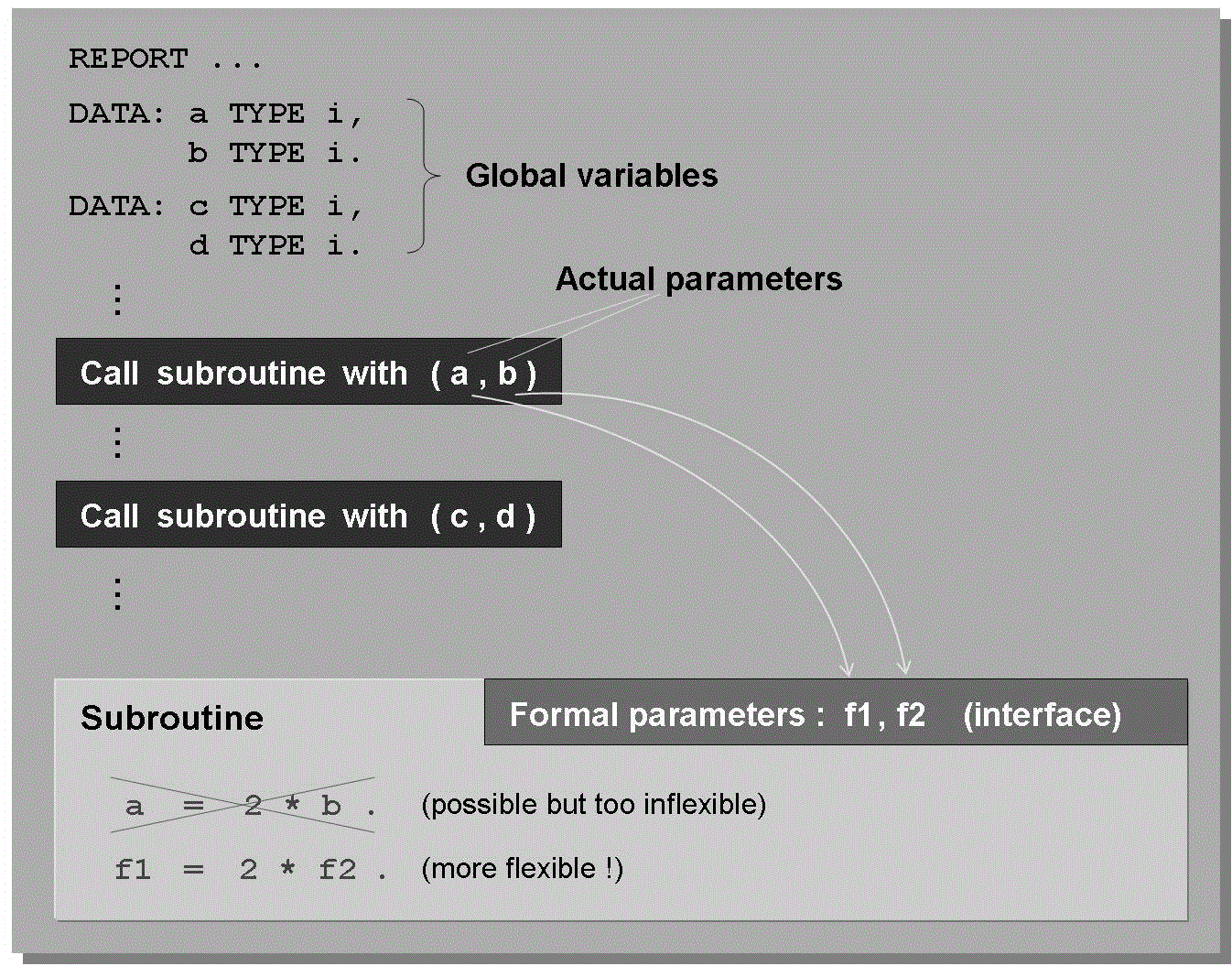
A Logical Database (LDB) is an ABAP program that reads data from the database
and makes the data available to report programs. This lesson provides an overview
of the features and structure of a logical database. It also lists the advantages of
using a logical database.
You can use either Open SQL or Native SQL statements to read data from the
database. Avoid using Native SQL to maintain portability from one RDBMS to
another. Also, Native SQL requires to be recoded to take advantage of upgrades in
the RDBMS. Open SQL has no such limitations or requirements.
The use of a logical database program provides an excellent alternative to
programming data retrieval. Logical databases retrieve data records in primary
key sequence and make the data available to ABAP programs. They also offer the
advantage of security because authority checks are made in the logical database
program rather than in the report program
A logical database is an ABAP program that reads data from the database and
makes the data available to other report programs.
A hierarchical structure determines the order in which the data is supplied to
programs. A logical database also provides a selection screen that checks user
entries and conducts error dialogs. You can add your own parameters and select
options.
The SAP system provides approximately 190 logical databases in Release 4.6.
The names of logical databases have been extended from three characters to 20
characters in Release 4.0 (namespace prefix maximum of 10 characters).
If the name of the logical database is three characters in length, the first two
characters name the logical database and the third character identifies the
application area. A list of the values for the third character can be displayed by
looking at a program’s attributes and then pressing F4 on the Application field. For
example, DDF is named for Debtor Data and the letter F represents financial data.

The following tables form the nodes of the logical database F1S:
• SPFLI: Flight connections
• SFLIGHT: Flights
• SBOOK: Bookings
You need to specify the name of the logical database in the program’s attributes
for an executable (type 1) program.
Use the keyword NODESto specify the nodes of the logical database
that you want to use in the program. NODES allocates appropriate storage space
for the node (a work area or a table area depending on the node type).
Note: The keyword TABLES can still be used in Release 4.6.data records,
it issues the statement PUTwhich triggers the GET event in
the report program.
Advantages of a Logical Database
A logical database can be the data source for several QuickViews, queries, and
reports. In QuickView, the logical database program (LDB) can be specified
directly as a data source. A query works with the logical database when the
InfoSet that generated the query is defined with a logical database. In the case
of executable programs, the LDB is entered in the attributes or called using the
function module LDB_PROCESS. See appendix for information on how to use
the function module.
Logical databases offer several advantages over other methods of data retrieval,
such as:
• The system generates a selection screen. The use of selection screen versions
or variants provides the required flexibility.
• The programmer does not need to know the exact structure or relationship of
the tables involved. The data ismade available to the application program in
primary key sequence. Performance improvements within logical databases
directly affect all programs linked to the logical database without having
to change the programs themselves.
• Maintenance and enhancements can be performed at a central location.
• Authorization checks are made in the logical database program rather than
in the application program.
Logical Database Subobjects and Data Retrieval
This lesson focuses on logical database (LDB) subobjects. The lesson begins with
an explanation of the structure of logical database subobjects. It explains how to
use selections in logical database subobjects. It also explains the importance of
database programs and the use of database program in logical database subobjects.
Finally, it explains how data is read from the database.
 Logical databases comprise of several subobjects. The structure determines the
Logical databases comprise of several subobjects. The structure determines the
hierarchy and the read sequence of data records.
Node names can contain up to 14 characters. There are four node types such as:
• Table (type T): The node name is the name of a transparent table. This node
type corresponds to the concept prior to Release 4.0A. The table name must
be identical to the node name. Deep types (complex) are not allowed.
• DDIC type (type S): Any node name is possible. The node is assigned a
structure or a table type from the Dictionary. The node name can differ from
the type name. Deep structures are possible.
• Type groups (type C): The node type is defined in a type group. The name of
the type group must be maintained in the Type group field. DDIC types are
generally preferred because other applications that use the logical database,
such as SAP Query, can access them (short texts, and so on).
• Dynamic nodes (type A): Do not have a fixed type and are not classified
until program run time. The types that are permitted are determined when
the structure is created.
 The START-OF-SELECTION event triggers before control is given to the
The START-OF-SELECTION event triggers before control is given to the
read routine of the logical database. The END-OF-SELECTION event triggers
after all GET events have been processed (all data records have been read and
processed).
The GETevent triggers when the logical database supplies data for this
node. This means that GET events are processed several times and that data has
already been read from the database for these events. The sequence in which GET
events are processed is determined by the structure of the logical database.
The GETLATE event triggers when all subordinate nodes of node
have been processed before the data is read for the next (when
a hierarchy level has been completed).
At the start of the event, the system automatically adds a line feed and sets the
font and intensity to the system defaults. If colors were set in other events, they
are reset.
The CHECK keyword ends the current processing block if the condition is false.
The STOP keyword ends program processing. Unlike the EXIT statement, the
processing block END-OF-SELECTION processes first (if it exists).
If there is a STOP statement within the END-OF-SELECTION processing
block, program processing ends and the list buffer is displayed.
The EXIT statement exits the program but does not trigger the
END-OF-SELECTION event. Any list buffer that was created before the EXIT
keyword is encountered will be displayed.
You can also use the REJECT statement. The data record does not process
further. Processing continues on the same hierarchy level when the next data
record is read. REJECT can also be used within a subroutine.
Logical database programs have an include named dbsel in which the
logical database selection screen(s) are defined. The addition FOR NODE assigns
selections to individual logical nodes. The appearance of a selection screen
directly depends on the NODES statement contained within your program.
A field selection can be defined in the logical database program for individual
nodes. This is done using the keyword FIELD SELECTION FOR NODE in the
SELECTION-SCREEN statement. The code in the logical database program
enables the application program to use the GETFIELD
list> to restrict the amount of data retrieved.
A few logical databases also designate dynamic selections for individual nodes.
This is done by dynamic selection using the addition DYNAMIC SELECTIONS
FOR NODE. The Dynamic selection button appears on the report’s selection
screen. You can determine which selection fields can be set by choosing a
particular selection view (type: CUS) or using the selection view delivered by
the SAP system (type: SAP).
A few large logical databases have several selection screen versions. Each
selection screen version contains a subset of the selection criteria (language
element: EXCLUDE). You can specify which selection screen to display by
entering the selection screen version number in the program attributes.
When you enter a logical database in the attributes of the type 1 program, the
system processes the selection screen of the logical database. The concrete
characteristics of the selection screen depend on the node specified in the NODES
statement. If you specify a node of type T (table), you can also declare the table
work area using the TABLES statement.
If you address only subordinate nodes (in the hierarchy) of the logical database in
the program (for example, SFLIGHT), the selection screen criteria for the superior
node in the hierarchy (SPFLI) also appears. You can thus restrict the dataset to be
read so that it meets specific requirements.
Note: A logical database always reads in accordance with its structure.
This means that if you need data only from a node deep in the hierarchy,
you should either find another logical database where the desired node is
higher in the structure or program data retrieval .
If the logical database supports dynamic selections, Dynamic selections appears
on the selection screen. When the user selects Dynamic selections, a second
selection screen is displayed, which enables the user to select additional database
fields. The system transfers the selections directly to the logical database program
and to the database (dynamic selections).
Logical database programs are named SAPDB for logical database
. The programs are a collection of subroutines, each of which is
performed for specific events. For example, subroutineis processed
once at the start of the database program. This program can define default values
for the selection screen of the LDB.
Other subroutines are processed during the event PBO (Process Before Output)
and PAI (Process After Input) of the selection screen. Checks such as authorization
checks (AUTHORITY-CHECK), are usually performed during the event PAI.
Database access (SELECT statements) is programmed in put_
subroutines. These subroutines may be processed several times depending on the
selection criteria specified by the user. The sequence in which these subroutines
are processed is determined by the structure of the logical database.
When a report program that uses a logical database is started, control is initially
passed to the database program of the logical database. Each event has a
corresponding subroutine in the database program (for example, subroutine init
for event INITIALIZATION). During the interaction between the LDB and the
associated report, the subroutine is always processed first, followed by the event
(if there is one in the report).
Logical database programs read data from a database according to the structure
declared for the logical database. They begin with the root node and then process
the individual branches consecutively from top to bottom.
The logical database reads the data in PUT_ subroutines. During event
PUT, control passes from the database program to the GET event of the associated
report. The data is made available in the corresponding work areas in the report.
The processing block defined for the GET event is performed and control then
returns to the logical database. PUT activates the next form subroutine found in
the structure. This flow continues until the report collects all the available data.
The depth of data read in the structure depends upon a program’s GET events.
A logical database reads to the lowest GET event contained within structure
attributes. Only those GET events for which processing is supposed to take place
are written in the report program. Logical databases read all data records found on
the direct access path.
If you specify a logical database and declare additional selections in the program
attributes that refer to the fields of a node not designated for dynamic selection,
you need to use the CHECKstatement to see if the current data
record fulfills the selection criteria.
If the data record does not fulfill these selection criteria, processing of the current
event block ends.
The selection view determines which fields are displayed on the selection screen.
Create your own view with type CUST and use it to override the view with type
SAP.
and makes the data available to report programs. This lesson provides an overview
of the features and structure of a logical database. It also lists the advantages of
using a logical database.
You can use either Open SQL or Native SQL statements to read data from the
database. Avoid using Native SQL to maintain portability from one RDBMS to
another. Also, Native SQL requires to be recoded to take advantage of upgrades in
the RDBMS. Open SQL has no such limitations or requirements.
The use of a logical database program provides an excellent alternative to
programming data retrieval. Logical databases retrieve data records in primary
key sequence and make the data available to ABAP programs. They also offer the
advantage of security because authority checks are made in the logical database
program rather than in the report program
A logical database is an ABAP program that reads data from the database and
makes the data available to other report programs.
A hierarchical structure determines the order in which the data is supplied to
programs. A logical database also provides a selection screen that checks user
entries and conducts error dialogs. You can add your own parameters and select
options.
The SAP system provides approximately 190 logical databases in Release 4.6.
The names of logical databases have been extended from three characters to 20
characters in Release 4.0 (namespace prefix maximum of 10 characters).
If the name of the logical database is three characters in length, the first two
characters name the logical database and the third character identifies the
application area. A list of the values for the third character can be displayed by
looking at a program’s attributes and then pressing F4 on the Application field. For
example, DDF is named for Debtor Data and the letter F represents financial data.

The following tables form the nodes of the logical database F1S:
• SPFLI: Flight connections
• SFLIGHT: Flights
• SBOOK: Bookings
You need to specify the name of the logical database in the program’s attributes
for an executable (type 1) program.
Use the keyword NODES
that you want to use in the program. NODES allocates appropriate storage space
for the node (a work area or a table area depending on the node type).
Note: The keyword TABLES can still be used in Release 4.6.data records,
it issues the statement PUT
the report program.
Advantages of a Logical Database
A logical database can be the data source for several QuickViews, queries, and
reports. In QuickView, the logical database program (LDB) can be specified
directly as a data source. A query works with the logical database when the
InfoSet that generated the query is defined with a logical database. In the case
of executable programs, the LDB is entered in the attributes or called using the
function module LDB_PROCESS. See appendix for information on how to use
the function module.
Logical databases offer several advantages over other methods of data retrieval,
such as:
• The system generates a selection screen. The use of selection screen versions
or variants provides the required flexibility.
• The programmer does not need to know the exact structure or relationship of
the tables involved. The data ismade available to the application program in
primary key sequence. Performance improvements within logical databases
directly affect all programs linked to the logical database without having
to change the programs themselves.
• Maintenance and enhancements can be performed at a central location.
• Authorization checks are made in the logical database program rather than
in the application program.
Logical Database Subobjects and Data Retrieval
This lesson focuses on logical database (LDB) subobjects. The lesson begins with
an explanation of the structure of logical database subobjects. It explains how to
use selections in logical database subobjects. It also explains the importance of
database programs and the use of database program in logical database subobjects.
Finally, it explains how data is read from the database.

hierarchy and the read sequence of data records.
Node names can contain up to 14 characters. There are four node types such as:
• Table (type T): The node name is the name of a transparent table. This node
type corresponds to the concept prior to Release 4.0A. The table name must
be identical to the node name. Deep types (complex) are not allowed.
• DDIC type (type S): Any node name is possible. The node is assigned a
structure or a table type from the Dictionary. The node name can differ from
the type name. Deep structures are possible.
• Type groups (type C): The node type is defined in a type group. The name of
the type group must be maintained in the Type group field. DDIC types are
generally preferred because other applications that use the logical database,
such as SAP Query, can access them (short texts, and so on).
• Dynamic nodes (type A): Do not have a fixed type and are not classified
until program run time. The types that are permitted are determined when
the structure is created.

read routine of the logical database. The END-OF-SELECTION event triggers
after all GET events have been processed (all data records have been read and
processed).
The GET
node. This means that GET events are processed several times and that data has
already been read from the database for these events. The sequence in which GET
events are processed is determined by the structure of the logical database.
The GET
a hierarchy level has been completed).
At the start of the event, the system automatically adds a line feed and sets the
font and intensity to the system defaults. If colors were set in other events, they
are reset.
The CHECK keyword ends the current processing block if the condition is false.
The STOP keyword ends program processing. Unlike the EXIT statement, the
processing block END-OF-SELECTION processes first (if it exists).
If there is a STOP statement within the END-OF-SELECTION processing
block, program processing ends and the list buffer is displayed.
The EXIT statement exits the program but does not trigger the
END-OF-SELECTION event. Any list buffer that was created before the EXIT
keyword is encountered will be displayed.
You can also use the REJECT statement. The data record does not process
further. Processing continues on the same hierarchy level when the next data
record is read. REJECT can also be used within a subroutine.
Logical database programs have an include named db
logical database selection screen(s) are defined. The addition FOR NODE assigns
selections to individual logical nodes. The appearance of a selection screen
directly depends on the NODES statement contained within your program.
A field selection can be defined in the logical database program for individual
nodes. This is done using the keyword FIELD SELECTION FOR NODE in the
SELECTION-SCREEN statement. The code in the logical database program
enables the application program to use the GET
list> to restrict the amount of data retrieved.
A few logical databases also designate dynamic selections for individual nodes.
This is done by dynamic selection using the addition DYNAMIC SELECTIONS
FOR NODE. The Dynamic selection button appears on the report’s selection
screen. You can determine which selection fields can be set by choosing a
particular selection view (type: CUS) or using the selection view delivered by
the SAP system (type: SAP).
A few large logical databases have several selection screen versions. Each
selection screen version contains a subset of the selection criteria (language
element: EXCLUDE). You can specify which selection screen to display by
entering the selection screen version number in the program attributes.
When you enter a logical database in the attributes of the type 1 program, the
system processes the selection screen of the logical database. The concrete
characteristics of the selection screen depend on the node specified in the NODES
statement. If you specify a node of type T (table), you can also declare the table
work area using the TABLES statement.
If you address only subordinate nodes (in the hierarchy) of the logical database in
the program (for example, SFLIGHT), the selection screen criteria for the superior
node in the hierarchy (SPFLI) also appears. You can thus restrict the dataset to be
read so that it meets specific requirements.
Note: A logical database always reads in accordance with its structure.
This means that if you need data only from a node deep in the hierarchy,
you should either find another logical database where the desired node is
higher in the structure or program data retrieval .
If the logical database supports dynamic selections, Dynamic selections appears
on the selection screen. When the user selects Dynamic selections, a second
selection screen is displayed, which enables the user to select additional database
fields. The system transfers the selections directly to the logical database program
and to the database (dynamic selections).
Logical database programs are named SAPDB
performed for specific events. For example, subroutine
once at the start of the database program. This program can define default values
for the selection screen of the LDB.
Other subroutines are processed during the event PBO (Process Before Output)
and PAI (Process After Input) of the selection screen. Checks such as authorization
checks (AUTHORITY-CHECK), are usually performed during the event PAI.
Database access (SELECT statements) is programmed in put_
subroutines. These subroutines may be processed several times depending on the
selection criteria specified by the user. The sequence in which these subroutines
are processed is determined by the structure of the logical database.
When a report program that uses a logical database is started, control is initially
passed to the database program of the logical database. Each event has a
corresponding subroutine in the database program (for example, subroutine init
for event INITIALIZATION). During the interaction between the LDB and the
associated report, the subroutine is always processed first, followed by the event
(if there is one in the report).
Logical database programs read data from a database according to the structure
declared for the logical database. They begin with the root node and then process
the individual branches consecutively from top to bottom.
The logical database reads the data in PUT_
PUT, control passes from the database program to the GET event of the associated
report. The data is made available in the corresponding work areas in the report.
The processing block defined for the GET event is performed and control then
returns to the logical database. PUT activates the next form subroutine found in
the structure. This flow continues until the report collects all the available data.
The depth of data read in the structure depends upon a program’s GET events.
A logical database reads to the lowest GET event contained within structure
attributes. Only those GET events for which processing is supposed to take place
are written in the report program. Logical databases read all data records found on
the direct access path.
If you specify a logical database and declare additional selections in the program
attributes that refer to the fields of a node not designated for dynamic selection,
you need to use the CHECK
record fulfills the selection criteria.
If the data record does not fulfill these selection criteria, processing of the current
event block ends.
The selection view determines which fields are displayed on the selection screen.
Create your own view with type CUST and use it to override the view with type
SAP.